Tune in for a free, live virtual hands-on lab...

Tune in for a free, live virtual hands-on lab...
Over this series of four posts, I explore the keys to a successful data warehouse. Last time, I started with design—a reasonable place to begin! The topic of this post is build, with operation and maintenance to follow.
Even with a beautiful design model in your mind’s eye, the question of how to build a data warehouse raises its ugly head! Ugly because no matter how lovely the model, implementation is always hobbled by the less than perfect reality of the data source systems. In the words of an old Irish joke in reply to a request for directions: “if I wanted to go there, I wouldn’t start from here.” Since the earliest days, builders of data warehouses have struggled with missing data in source systems, poorly defined data structures, incorrect content, and missing relationships, to name but a few. Implementation, therefore, becomes a delicate balancing act between the vision of the model and the constraints of the sources. In simplistic terms, the process comes down to the following steps.
Often described as data archeology, this step presents major challenges, especially for legacy systems, which—even if originally well documented—have usually been “bent to fit” emerging and urgent requirements. Modern big data sources may be equally challenging as a result of poor or absent documentation.
Compare the data available to the data warehouse model and define appropriate transformations to convert the former to the latter.
Where transformations are too difficult, modify the data warehouse model to accommodate the reality of the data sources. Changing the data sources—which would be the right answer when they are in error—is usually impossible for reasons of cost, politics, or both.
Test performance of load/update processes and check ability of modified model to deliver the data needed by the business.
If successful, declare victory. Otherwise, rinse and repeat.
Traditionally, the output of the above process would be encoded in a script or program and run—typically overnight in batch—to populate the warehouse. Any changes in requirements or, more problematically, in the source systems (beyond the control of the data warehouse developers) required a round trip back through steps 1 to 5, followed by code update. The approach is manual, time-consuming, and error-prone.
The solution over the years has been to automate the process in a series of approaches: ETL (extract, transform, load) tools, data integration systems, and latterly, data warehouse automation (DWA). In essence, each step on this journey depicts an increasing level of automation, with DWA designed to address the entire process of design, build, operation, and maintenance.
In the transition from design to build, the combination of a well-structured data model and a DWA tool such as WhereScape® RED offers a particularly powerful approach to automation. This is because the data model provides an integrated starting set of metadata that describes the target tables in both business terms and technical implementation. This is particularly true in case of the Data Vault model, which has been designed and optimized from the start for data warehousing.
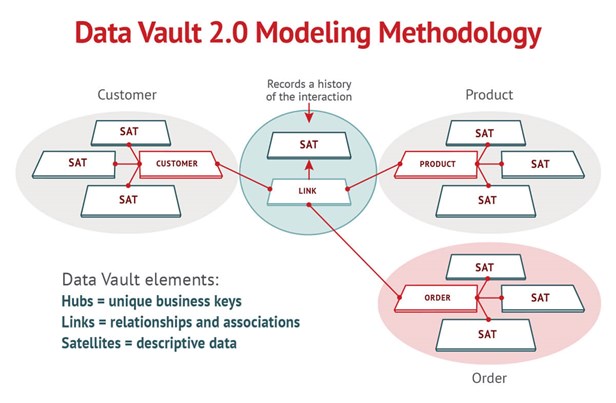
Consider, for example, the business need to analyze orders by value and geographical source. To the business person, order seems a simple, straightforward concept. In modeling terms, of course, it consists of a rather complex combination of entities, including product and person/customer. The structure to be built is equally intricate in terms of tables and the relationships between to them. The Data Vault model provides a database template for that structure, mapping directly from the business entities to a best practice set of data elements—from tables and columns through to relationships to indexes.
A DWA tool automates the transformation of the data structures of the various sources to the optimized model of the Data Vault and populates the target tables with the appropriate data, creating necessary indexes, and cleansing and combining source data to create the basis for the analysis needed by the business. WhereScape® Data Vault Express™ provides the underlying templates to automatically and quickly build all the required structures (tables, indexes, etc.) and processes (ETL code) without manual programming and optimized for the chosen implementation platform, such as Teradata, Oracle, Microsoft, etc.
But, it’s about more than automating programming. In the future, Data Vault Express plans to address further build-time elements, including the methodology and best delivery practices defined by the Data Vault community, to avoid design errors and support proper auditing and management of the warehouse environment. That leads us to part three of this series.
You can find the other blog posts in this series here:
Dr. Barry Devlin is among the foremost authorities on business insight and one of the founders of data warehousing, having published the first architectural paper on the topic in 1988. Barry is founder and principal of 9sight Consulting. A regular blogger, writer and commentator on information and its use, Barry is based in Cape Town, South Africa and operates worldwide.
In working with hundreds of data teams through WhereScape’s automation platform, we’ve seen this debate evolve as businesses modernize their infrastructure. Each method, ETL vs ELT, offers a unique pathway for transferring raw data into a warehouse, where it can be...
Kimball’s dimensional modeling continues to play a critical role in machine learning and data science outcomes, as outlined in the Kimball Group’s 10 Essential Rules of Dimensional Modeling, a framework still widely applied in modern data workflows. In a recent...
Automating Data Vault in Databricks can reduce time-to-value by up to 70%—and that’s why we hosted a recent WhereScape webinar to show exactly how. At WhereScape, modern data teams shouldn't have to choose between agility and governance. That's why we hosted a live...
Big Data & AI World London 2025 brought together thousands of data and AI professionals at ExCeL London—and WhereScape was right in the middle of the action. With automation taking center stage across the industry, it was no surprise that our booth and sessions...
Optimizing Healthcare Data Management with Automation Healthcare organizations manage vast amounts of medical data across EHR systems, billing platforms, clinical research, and operational analytics. However, healthcare data integration remains a challenge due to...
During our latest WhereScape webinar, attendees had fantastic questions about Data Vault 2.0, Databricks, and metadata automation. We’ve compiled the best questions and answers to help you understand how WhereScape streamlines data modeling, automation, and...
As of 2023, the global data fabric market was valued at $2.29 billion and is projected to grow to $12.91 billion by 2032, reflecting the critical role and rapid adoption of data fabric solutions in modern data management. The integration of data fabric solutions...
Understanding the AI Landscape Imagine losing 6% of your annual revenue—simply due to poor data quality. A recent survey found that underperforming AI models, built using low-quality or inaccurate data, cost companies an average of $406 million annually. Artificial...
For years, WhereScape RED has been the engine that powers rapidly built and high performance data warehouses. And while RED 10 has quietly empowered organizations since its launch in 2023, our latest 10.4 release is a game changer. We have dubbed this landmark update...
Imagine an old-fashioned assembly line. Workers pass components down the line, each adding their own piece. It’s repetitive, prone to errors, and can grind to a halt if one person falls behind. Now, picture the modern version—robots assembling products with speed,...

In working with hundreds of data teams through WhereScape’s automation platform, we’ve seen this debate evolve as businesses modernize their infrastructure. Each method, ETL vs ELT, offers a unique pathway for transferring raw data into a warehouse, where it can be...

Kimball’s dimensional modeling continues to play a critical role in machine learning and data science outcomes, as outlined in the Kimball Group’s 10 Essential Rules of Dimensional Modeling, a framework still widely applied in modern data workflows. In a recent...

Automating Data Vault in Databricks can reduce time-to-value by up to 70%—and that’s why we hosted a recent WhereScape webinar to show exactly how. At WhereScape, modern data teams shouldn't have to choose between agility and governance. That's why we hosted a live...

In working with hundreds of data teams through WhereScape’s automation platform, we’ve seen this debate evolve as businesses modernize their infrastructure. Each method, ETL vs ELT, offers a unique pathway for transferring raw data into a warehouse, where it can be...

Kimball’s dimensional modeling continues to play a critical role in machine learning and data science outcomes, as outlined in the Kimball Group’s 10 Essential Rules of Dimensional Modeling, a framework still widely applied in modern data workflows. In a recent...

Automating Data Vault in Databricks can reduce time-to-value by up to 70%—and that’s why we hosted a recent WhereScape webinar to show exactly how. At WhereScape, modern data teams shouldn't have to choose between agility and governance. That's why we hosted a live...

Big Data & AI World London 2025 brought together thousands of data and AI professionals at ExCeL London—and WhereScape was right in the middle of the action. With automation taking center stage across the industry, it was no surprise that our booth and sessions...