In society and in our organizations, we need a healthy balance between creativity and process. One prevents the other from stagnating or getting out of control. We must progress with structure and balance to innovate effectively. The same is true in our data ecosystems.
Data lakes and data warehouses are both methods of panning for gold, aiming to distill actionable data insight but using different approaches. We often hear people talk about lakes and warehouses as if we must choose one or the other. In reality, they serve different purposes and are complementary. While both provide storage for data that can be queried for analytical purposes, each has a different structure, supports different formats, and is optimized for different uses.
This article studies the benefits of data lakes and data warehouses before exploring how they can be assimilated most effectively using automation software.
Why Use a Data Lake?
With the pace of change in data technology, it’s hard to predict how we will use the data we ingest now in the future. Data lakes are useful because you don’t have to prep or clean the data before storing it so that you can retain as much potential value as possible for future use.
Artificial Intelligence and Machine Learning can represent limitless opportunities for data scientists, but also potentially large and expensive workloads. For these reasons, organizations are increasingly turning to data lakes to help store large amounts of unstructured data that can be accessed by a wide variety of services.
This can range from raw to semistructured data and varying grades of curated data sets. A data lake gives a variety of consumers access to the appropriate data for their needs, but it can be stored relatively cheaply, without the need to use ETL or ELT to ingest it into a data warehouse.
Why Use a Data Warehouse?
Data lakes and the exploratory technologies that unstructured big data enables are only as useful as your company’s ability to assimilate their findings into a structured environment. This is where the data warehouse takes over: a data lake can be added as a source to a data warehouse, and its data blended with other real-time and batch sources to provide rich, contextualized business insight.
Originally data warehouses were used to store and organize data, but now they support and drive business processes. The data warehouse is no longer playing catch-up. Today we can spin up prototype designs in minutes and get our infrastructure up and running in days. We use cloud platforms like Snowflake and Microsoft Azure Synapse to run queries in seconds and only pay for the amount of compute and processing power we need. The choice of database is no longer a ten-year decision, given how much easier it is to migrate using metadata-driven tools.
Data is Inevitable but Information is Not
While the exponential growth of data makes more insight available, it also means the infrastructure that stores and analyses it becomes necessarily more complex. This infrastructure needs to adapt as new demands emerge (constantly) and as data sources evolve (periodically). It’s a fallacy to think we can create the ultimate data infrastructure that won’t need to be changed.
It is possible, however, to design and build for change, and pairing a data lake and a data warehouse together gives the most agile framework for getting rapid insight from conventional and big data ingestion now and in the future. So how do we add structure to this rich but complex data fabric? While many companies will offer huge teams of expensive data wizards to do the job, in reality, we cannot hope to harness its potential effectively without automating time-consuming, repeatable processes.
With the automation technology available today, these complex processes can be abstracted into an orchestration layer, from which IT teams can maintain control without having to do the menial tasks by hand.
Data Warehouse Automation
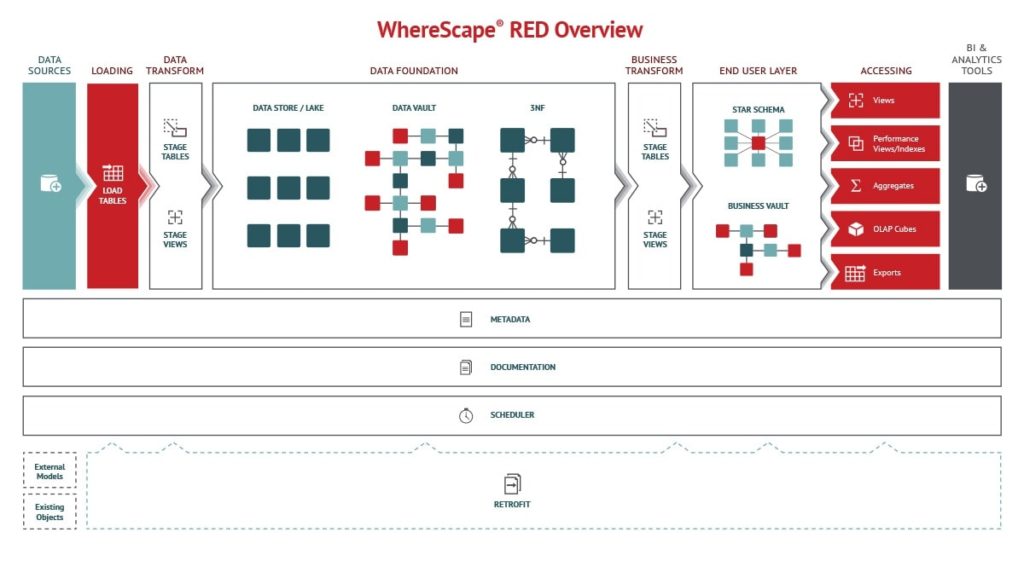
Software such as WhereScape puts a simplifying model on top of your existing data ecosystem to make it far easier, faster, and cheaper to build a complex and powerful data warehouse. Staff can design structures in a drag and drop GUI, build prototypes with actual company data, then once all requirements have been agreed upon, the tool physicalizes the model by generating thousands of lines of code, essentially doing many weeks of hand-coding work in seconds. This enables teams to produce usable infrastructure in days, not months.
WhereScape is metadata-driven, which means that every action taken is recorded in metadata and stored in a repository. Therefore, documentation can be produced at the touch of a button, with full lineage, and enables track-back and track-forward functionality.
Data Lake Automation
The data lake platform such as Qubole provides end-to-end services that reduce the time, effort, and cost required to run data pipelines, streaming analytics, and machine learning workloads on any cloud.
For ad hoc and streaming analytics, the platform’s workbench allows the data team to author, save, collaborate and share reports and queries. Qubole enables the Data Analytics team to develop and deliver ad-hoc SQL analytics through optimized ANSI/ISO-SQL (Presto, Hive, SparkSQL) and third-party tools such as Tableau, Looker, and Git native integrations. The Data Analytics team can build streaming data pipelines, combine them with multiple streaming, and batch datasets to gain real-time insights.
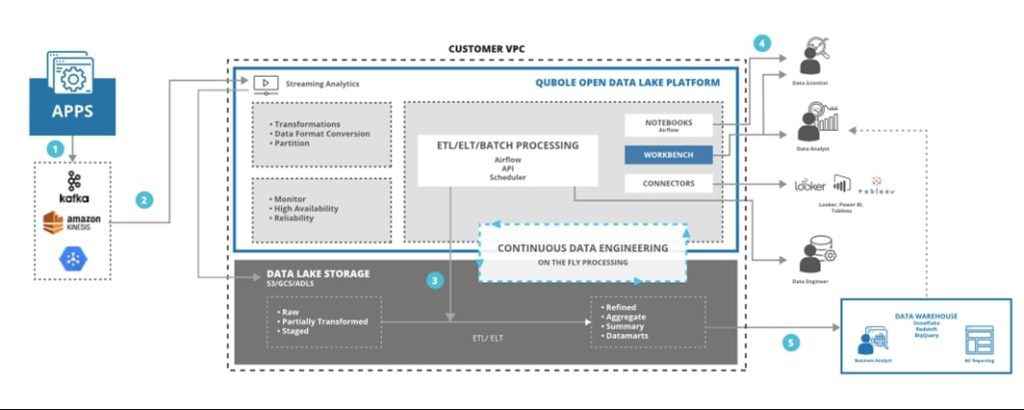
Qubole’s ML-specific capabilities such as offline editing, multi-language interpreters, and version control deliver faster results. Qubole supports data scientists with comprehensive support for Jupyter Notebooks, Spark, Tensorflow, and Scala, as well as integrations with ML tools like RStudio, Sagemaker, and others. It provides the data science team to access all their data and tools they need to build predictive analytical models in collaboration with each other and the other data teams across the enterprise.
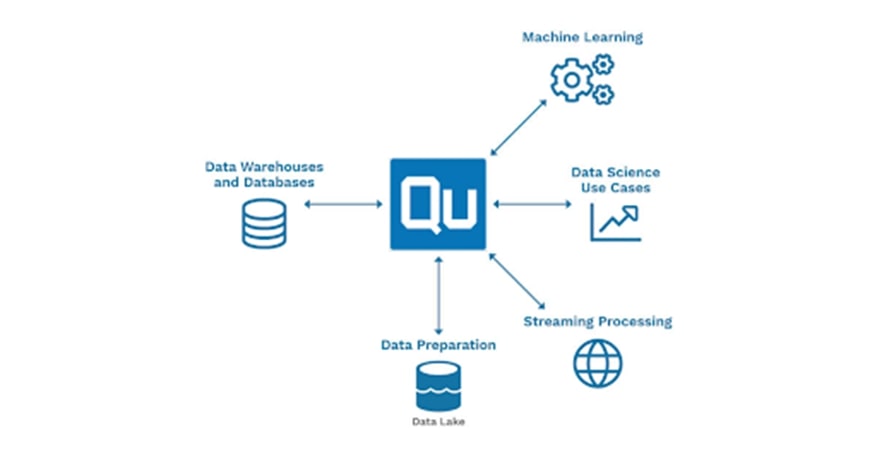
The platform automates pipeline creation, scale, and monitoring allowing the data team to easily create, schedule, and manage workloads for continuous data engineering. Use the processing engine and language of choice like Apache Spark, Hive, Presto with SQL, Python, R, and Scala.
Qubole reduces complexity at the data management level and eliminates infrastructure complexity besides providing a near-zero administration experience for the Data Admin teams by automating the mundane daily tasks needed to provide users with access to your data. It puts saving costs first for customers which can be reinvested in use cases, running more workloads, deriving more results.
The platform runtime automates the cloud infrastructure provisioning, deployment and further optimizes it with workload-aware autoscaling, cluster lifecycle management, intelligent spot management, heterogeneous cluster management to give the best TCO industry-wide. In addition, Qubole has built-in security and governance controls which are enterprise-grade. Like, providing ACID compliance for granular read writes for GDPR and CCPA compliance, RBAC, and IAM integrations with cloud providers.
Qubole even provides built-in integrations with solutions like Big Query, and AWS Data Lake Formation as well as providing the ability to integrate other processes with your data through the Qubole platform APIs and SDKs.
In Conclusion
The danger of not knowing precisely what each structure does, or viewing them as an either/or choice, is that we can miss out on the potential agility and business value of using a data lake and a data warehouse in conjunction. As our data fabric becomes more complex, the need for a diverse portfolio of analytical tools becomes more useful, and a symbiosis of lake and warehouse makes increasingly more sense.


